Overview
Around 42 million people play fantasy football every fall, hoping to outsmart their friends and family and win a coveted fantasy championship. Fantasy football usually uses stats from the NFL, the highest level of football play in the world. As a result, college and high school level football are rarely included in fantasy football apps like ESPN and Sleeper. So, being a high-school football fanatic, I decided to create a fantasy football “app” using stats from my high-school’s league. This article will detail my process in creating the app, my challenges, and my sources.
Background
Most fantasy apps create their own rankings using previous player performances and free agency. Once these rankings are released, teams will draft a quarterback, running-back, wide-receiver, tight-end, kicker, a defense, and multiple bench players. When the draft finishes, each team will receive a draft grade. Draft grades vary based on the fantasy app but they all use their projected rankings in their calculations. Once a grade is given, players will use that information to better their team by trading and picking up new players in free agency.
My Plan
- Predict fantasy performance of the players using training data from the NFL
- Create my own system of ranking players using prediction and position value
- Find a way to grade the draft picks
- Create a draft simulator
The Prediction
Advice: Predicting NFL player performance is a much easier starting project(I recommend it). With hundreds of datasets and analysis, NFL ML projects can be easier to code and there’s less of a hassle with formatting data.
Now, let’s get into the good stuff.
When I was beginning this project, I found enough data to create a list of draftable players but not enough to predict player performance. So, I decided to use NFL data instead to train my model. Thanks to Benjamin Abraham’s fantasy football project, I was able to collect data from the last 10 years and create a model of 66% testing-accuracy using a simple linear regression. However, I found the accuracy to be too low so I decided to make some changes.
My first change was to remove the age parameter, which I considered unrelated to my current goal. Age matters a lot in the NFL because as you get older, your body deteriorates which then hurts your performance. At the high school level, all the players are relatively young and have had less injuries than their NFL counterparts. As a result, I removed age from my list of parameters for all positions.
#removed age parameter
if position == 'QB':
X = df[['PassAtt/G','PassYds/G', 'PassTD/G', 'RushAtt/G', 'Y/A','RushYds/G','RushTD/G', 'TotTD/G','PPG','VBD']] elif position == 'RB':
X = df[['RushAtt/G', 'Y/A','RushYds/G', 'RushTD/G','Rec/G','RecYds/G','Y/R','RecTD/G','TotTD/G','PPG','VBD']]
elif position == 'WR' or 'TE':
X = df[['Rec/G','RecYds/G','Y/R', 'RecTD/G','TotTD/G','PPG','VBD']]
Creating a Ranking System
You might have a few questions at this point regarding the need of a ranking system. Well, it all comes down to availability and positional value. In fantasy football, each position has a different value. Usually, WRs and RBs have more value than QBs and TEs due to their ability to catch the ball reliably. In conjunction with that, there are less high scoring RBs and WRs than QBs, a low supply but a high demand. As a result, running-backs and wide-receivers should have a higher value then other positions. This idea is known as biased draft value.
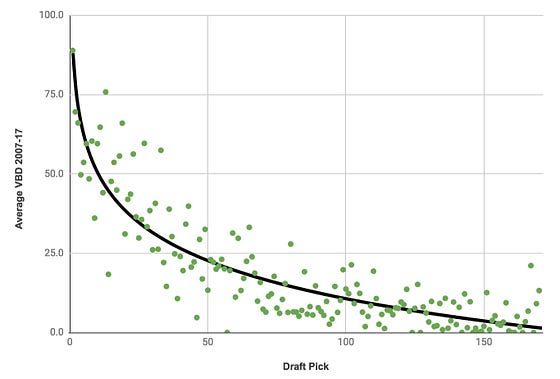
VBD
Draft Simulator
For the simulator, I had to store and update each team regularly so I decided to use csv files. Because there are 8 teams, I had to create 8 separate csv files with the headers: Position, Name, VBD, and Score.
Position,Name,VBD,Score
QB,,,
RB,,,
WR,,,
TE,,,
FLEX,,,
K,,,
DST,,,
Bench1,,,
Bench2,,,
Bench3,,,
Using pandas and the .read_csv function, I stored the csv data in a dataframe, making it easier for data manipulation. Then, each team has its own function, taking in 3 inputs: Position, Name, and VBD. I then add the inputs into the csv and save it. So, if the program crashes in the middle of the draft, all the data will be saved. After the csv is updated with the draft pick, using the draft analysis algorithm, the script calculates the draft score and saves it in the score column.
def t1():
position = input("Enter position: ")
name = input("Enter name: ")
vbd = float(input("Enter VBD: "))
df_t1.loc[position, 'Name'] = name
df_t1.loc[position, 'VBD'] = vbd
df_t1.to_csv('t1.csv')
change = calc(count) - vbd
global t1_score
t1_score = t1_score - (4*change)
df_t1.loc['QB','Score'] = t1_score
df_t1.to_csv('t1.csv')
Then, using two functions called firstround() and secondround(), the simulator imitates the snake draft.
def firstround():
global count
t1()
count+=1
print("------Pick Number: " + str(count) + " ------")
t2()
count+=1
print("------Pick Number: " + str(count) + " ------")
t3()
count+=1
print("------Pick Number: " + str(count) + " ------")
t4()
count+=1
print("------Pick Number: " + str(count) + " ------")
t5()
count+=1
print("------Pick Number: " + str(count) + " ------")
t6()
count+=1
print("------Pick Number: " + str(count) + " ------")
t7()
print("------Pick Number: " + str(count) + " ------")
count+=1
t8()
count+=1def secondround():
global count
print("------Pick Number: " + str(count) + " ------")
t8()
count+=1
print("------Pick Number: " + str(count) + " ------")
t7()
count+=1
print("------Pick Number: " + str(count) + " ------")
t6()
count+=1
print("------Pick Number: " + str(count) + " ------")
t5()
count+=1
print("------Pick Number: " + str(count) + " ------")
t4()
count+=1
print("------Pick Number: " + str(count) + " ------")
t3()
count+=1
print("------Pick Number: " + str(count) + " ------")
t2()
count+=1
print("------Pick Number: " + str(count) + " ------")
t1()
count+=1
Takeaways
Even though I had to gather and format the data for quite some time, I had a great time working on this project. I learned a lot about building models and creating new tools for data analysis using python.
GitHub – SreekarKutagulla/WCAL_FantasyFootball: Fantasy Football for WCAL
You can’t perform that action at this time. You signed in with another tab or window. You signed out in another tab or…
Hi, my name is Sreekar Kutagulla. I am a 16 year old developer from the Bay Area. Check out my sports analytics work with Lancer Analytics and my Github. Thanks for reading!


